CONTRIBUTIVE RESEARCH: HYPOTHES.IS IMPLEMENTATION FOR ACADEMIC RESEARCH PURPOSE
In reply to Call for Linked Research Workshop: Researcher Centric Scholarly Communication (April 24th, 2018) – Giacomo Gilmozzi, Vincent Puig and Yves-Marie Haussonne.
Abstract: The web was originally conceived and developed to meet the demand for automatic information-sharing between scientists in universities and institutes around the world. At IRI, we want to go back to this vision and develop digital tools that enable the contributory construction of meaning, understanding and knowledge. In this article (and in this workshop) we propose to analyze the interest of the categorized contributive annotation model currently tested on three ongoing research projects. This tool has been developed on the basis of a modification of the hypothes.is platform inspired by the work of the W3C Open Annotation group. In particular we analyze three functions: the group dynamics and related problems inspired by the philosophy of G. Simondon (Hui and Halpin, 2012, [1]), the use of meta-categories for transindividuation, and the contributive publication of a glossary.
I. The web we want
We think that the web we are dealing with is not the web we want. This current version of the web is the digital translation of the mainstream economic way of thinking: neoliberalism. But we also think that the web is not (or will not be) necessarily the place of continuous and uninterrupted production of functional stupidity [2]. Using Bernard Stiegler’s vocabulary, the web we want is hermeneutical, negentropic [3], deliberative and contributive: it is the milieu of production of knowledge and know-hows. This is why at IRI we chose to develop some digital tools that can rehabilitate web’s hermeneutical and contributory functions that were at the core idea of the Internet. The one we want to present you at the Researcher Centric Scholarly Communication Workshop is an annotation platform based on the modification we have implemented on the Hypothes.is project and inspired by the W3C Open Annotation group.
In the past years we have developed the idea of a contributive research that inherits two main features. The first one are the principles of action-research, where researchers are not seen as mere observers of the facts of societies but also as contributors to their evolution. The second is the conception of knowledge production that depends on shared digital instruments and organs. This epistemological framework is what Bernard Stiegler calls the general organology [4], a framework shared by the international network Digital Studies (http://digital-studies.org), the journal Etudes Digitales (http://etudes-digitales.fr/) and which is being tested by IRI and its researchers in three experiments [5].
The contributive research has taken on a new dimension with the development of participatory sciences [6]. It can go, in digital context, from a simple production of navigation traces – main object of the data economy and social networks – up to forms of controlled tagging, contributive editing/aggregation (e.g. Wikipedia), editorial and commentary (micro-film reviews) or original publication (blogs). We propose to analyze the interest of our categorized contributive annotation model questioning the socio-technical functions of the contribution – annotation, indexing, categorization, visualization, group formation, group recommendation and editorialization – by showing how these functions articulate more or less with the algorithmic processing of data.
II. The Hypothes.is Platform Implementations: Meta-categories and Editorialization
Hypothes.is is an open source software project which aim is to give to users a conversation layer over the entire web without needing implementation of any underlying site. In the academic world, it allows researchers to share knowledge on articles, discuss concepts, and then see if there is consensus, but also to analyze the evolution of these controversies in one or more workgroups. Thus, it can speed up while ameliorating the academic research process thanks to the contribution of the various members of a given group. An annotation can thus be private, shared within a group or public. For our purposes, we focus only on annotations that are shared within one (or multiple) group. The group is in fact the condition of possibility for the individuation of the individuals. Meta-categories. On top of the basic features already available in Hypothes.is[8], we decided to implement another function. We created four meta-categories (important, keyword, comment and trouble) which are easily recognized by the users thanks to the different colors with which annotations are highlighted – see Fig. 1 below and Fig. 2.
Fig. 1 The Annotation Protocol.
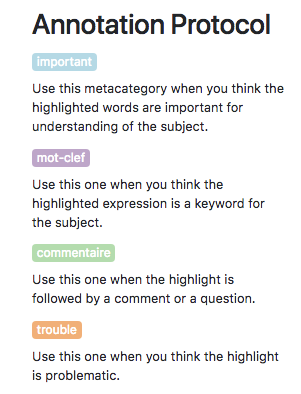
Fig. 2 Example of annotated page.
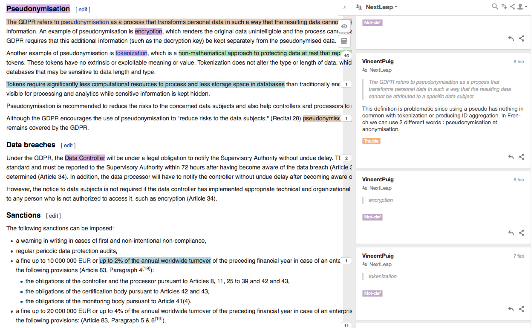
Once we highlight a word, a sentence or a paragraph, we can choose between the four meta-categories. As we have seen, the annotations will be highlighted with the color of the chosen category (see Fig. 1 and Fig. 2). This is important to give a sudden idea of what the annotation is referring to. In our experience, annotated texts are easier to understand and quicker to read. This means that researcher can work better and faster. Once we have selected our meta-category, we can post the annotation to the group. Like in the Hypothes.is project, there is also the possibility to leave comments or short analysis in a box (Fig. 3) that helps the members of the group to explain themselves and call for expertise, discussion, to raise a point or a question. A dashboard (Fig. 4, p. 7) has been conceived to visualize the use of metacategories. It is the starting place for trans- individuation, that is to say the formation of a subject which is partially determined by its group and cultural environment. Users can look through group-annotations, filtering them by metacategory, document or contributor, prioritize them and helping to resolve the controversies.
Fig. 3 Comment box.
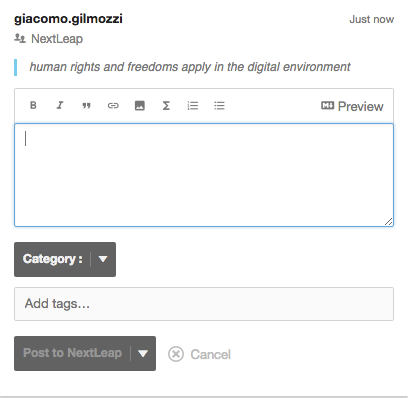
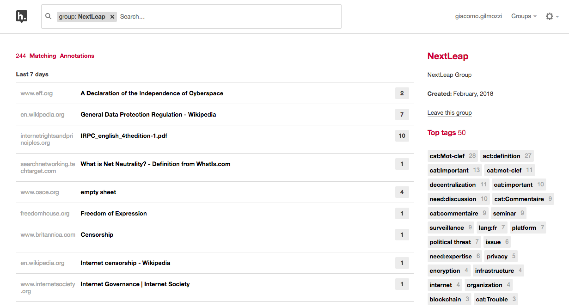
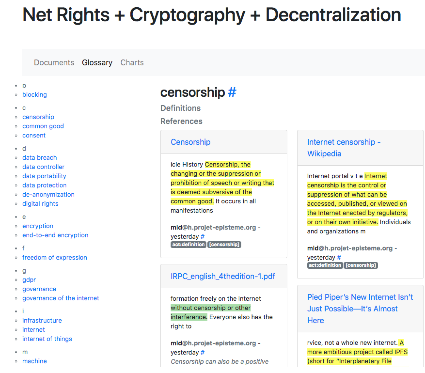
Fig. 4 NetRights Glossary
Editorialization.
IRI has also developed various functions concerning the automatic editorialization of the data collected through annotations. One example is the NetRights-Glossary that we have developed in the context of NextLeap project, an EU funded project that brings together cryptographers, philosophers and sociologists. This glossary is constituted by all the annotations categorized as key-words. Theirs definition(s) are given either by contributors themselves or taken from an external website. It is accessible to all the group members and it permits to create a shared vocabulary for the group (Fig. 5). The glossary support multiple keyword definitions, in line with the interdisciplinary and organological approach supported by the Digital Studies Network and IRI. Furthermore, contributors’ name, the web-reference and the context from which citations are taken are always visible, in line with the academic process of knowledge building. Statistic charts are built automatically while annotating, displaying which kind of category and how many times they have recurred in a given document.
Fig. 5 NetRights Glossary.
Future developments for data editorialization.
We are also developing a discussion forum for the keywords presenting problematic or antithetic definitions. In this forum, contributors will have the possibility to discuss about the relevance of the different definitions in order to engage into controversies according to the aim of their research. Another function which is being developed is the automatic editorialization and publication of abstract in a predetermined format with data collected via annotations, the creation of conceptual map summing up the consensus or the dissensus and also automatic to-do-lists based on the action category (act:expertise, act:meeting, etc.).
III. Research problems: The Simondonian model
a) How to go from individual-centered to group-centered social network?
In 2012, in the context of the Arab spring revealing serious threats against individual communication, Harry Halpin and Yuk Hui conducted a research project at IRI9 in order to design social networks alternative to the FB principle of maximizing the individual bubble (EdgeRank). Following philosopher Gilbert Simondon individuation theory, they proposed social networks where the group (first entry point) may produce knowledge enriching individuals. Furthermore, Yuk Hui recently argued that the group is in itself a protection of personal data and may provide efficient mechanism for inter-group recommendation (Beyond personalization and anonymity: Towards a group-based recommender system, S Shang, Y Hui, P Hui, P Cuff, S Kulkarni - Proceedings of the 29th Annual ACM Symposium on …, 2014). This research topic is debated in the Nextleap project for which we developed an Hypothes.is platform for NetRights contribution.
b) How to develop native group-based annotation?
Within the current Hypothes.is data model, contributors may log in a group but only for reading purposes. After writing an annotation they need to publish selecting every time the desired groups. This is not favoring native group-based individuation where reading and writing should not be separated and where every action should be seamlessly visible to all the group members. The Hypothes.is platform implementations are intended to move towards the Simondonian social- network model by setting the contributors’ transindividuation at the center of its purposes. As Hui and Halpin write:
« the ‘group’ [is] based around a common project or calling [which is][…] a projection, that is, the anticipation of a common future of the collective individuation of groups. By tying groups to projects, we hold to the fact that individuation is also always a temporal and existential process, rather than merely social and psychological. By projecting a common will to a project, it is the project itself that produces a co-individuation of groups and individuals. Fur- thermore, by creating a new technical substrate influenced by open standards that are based on this conception of groups, different alternatives can exchange and make elements of their social networks communicable in terms of protocols, data portability, and especially conceptualizations. So while we criticize the limits of social networks and researchers who embrace sociometry as some royal road to understanding social computing, we also want to outline that a new method for understanding – and even programming! – the social and digital is possible, and urgent. »
These are the guidelines that are also drawing our path to what we want to develop within the PIA project in Plaine Commune (Territoire Apprenant Contributif) with a deliberative, decentralized and contributive platform for involving citizens at the local level over data deliberation collected by private and public actors.
————————————————————————————————————————————————————————————————————
Notes
[1] See https://www.iri.centrepompidou.fr/projets/socialweb/ .
[2] Functional stupidity, as Alvesson and Spicer wrote in their book called The Stupidity Paradox, is the inability and/or unwillingness to use cognitive and reflective capacities in anything other than narrow and circumspect ways. It involves a lack of reflexivity, a disinclination to require or provide justification, and avoidance of substantive reasoning.
[3] Cfr. Stiegler B. (dir.) (2017). La toile que nous voulons. Paris, FYP éditions. With hermeneutical, Stiegler means a web based on interpretation functions (reading, annotating, sharing, categorizing, editorializing and publishing) of texts, videos and images and in line with the tools developed at the Institut de Recherche et Innovation. With negentropic web, the french philosopher means a web which is also the place for the production of knowledge and know-hows and so to diversity-in-order.
[4] The organology in music classifies and describes the instruments, by extension and in reference to the Organon of Aristotle, we recover this term to designate a general organology, which covers the technical, social and biological conditions of the production of knowledge.
[5] Cfr. Contributing Learning Territory project (TAC) for the development of a contributive economy in the north of Paris; in the framework of the ANR Épisteme project for the production of knowledge in astrophysics https://projet-episteme.org/. And finally for the discussion on Net-Rights in the NextLeap European project https://nextleap.eu/projects/rights.html.
[6] Which includes contributors in the observation and analysis of biodiversity (see in France the success of the site vigie-nature of the Museum National d’Histoire Naturelle), of the natural environment or astronomical data.
[7] See G. Simondon, L’individuation psychique et collective (1989). See also the Ars Industrialis Vocabulary: http://arsindustrialis.org/vocabulaire-ars-industrialis/transindividuation#sdfootnote2anc .
[8] See the following link for a graphic explanation of Hypothes.is’ functions : https://web.hypothes.is/#features.
[9] Within the SocialWeb project. See https://www.iri.centrepompidou.fr/projets/socialweb/.